
Cross Validation and Hyperparameter Tuning Explained
The Interview Guide to Model Selection and Generalization

Over the past few issues of The Practical Data Scientist, we’ve explored several machine learning models, from Logistic Regression and Decision Trees to Random Forests and XGBoost.
But regardless of how powerful a model may be, one question remains: how do we know if it will perform well on unseen data?
Suppose we train two models and obtain the following training accuracies:
Model A: 99%
Model B: 95%
Which model is better?
At first glance, Model A might seem like the obvious choice. However, training performance alone tells us very little about how the model will behave in the real world.
A model that performs exceptionally well on the training data may simply be memorizing it rather than learning patterns that generalize to new observations. This phenomenon, known as overfitting, is one of the most common challenges in machine learning.
To build models that generalize well, we need reliable ways to estimate their performance on unseen data and systematic approaches for choosing their settings.
This is where cross validation and hyperparameter tuning come into play.
In this issue, we’ll explore how to properly evaluate machine learning models, understand why a single train-test split is often not enough, and learn how to tune models to achieve better performance without falling into common pitfalls.
By the end of this issue, you’ll understand one of the most important ideas in machine learning:
“A model is only as good as the way it is evaluated”
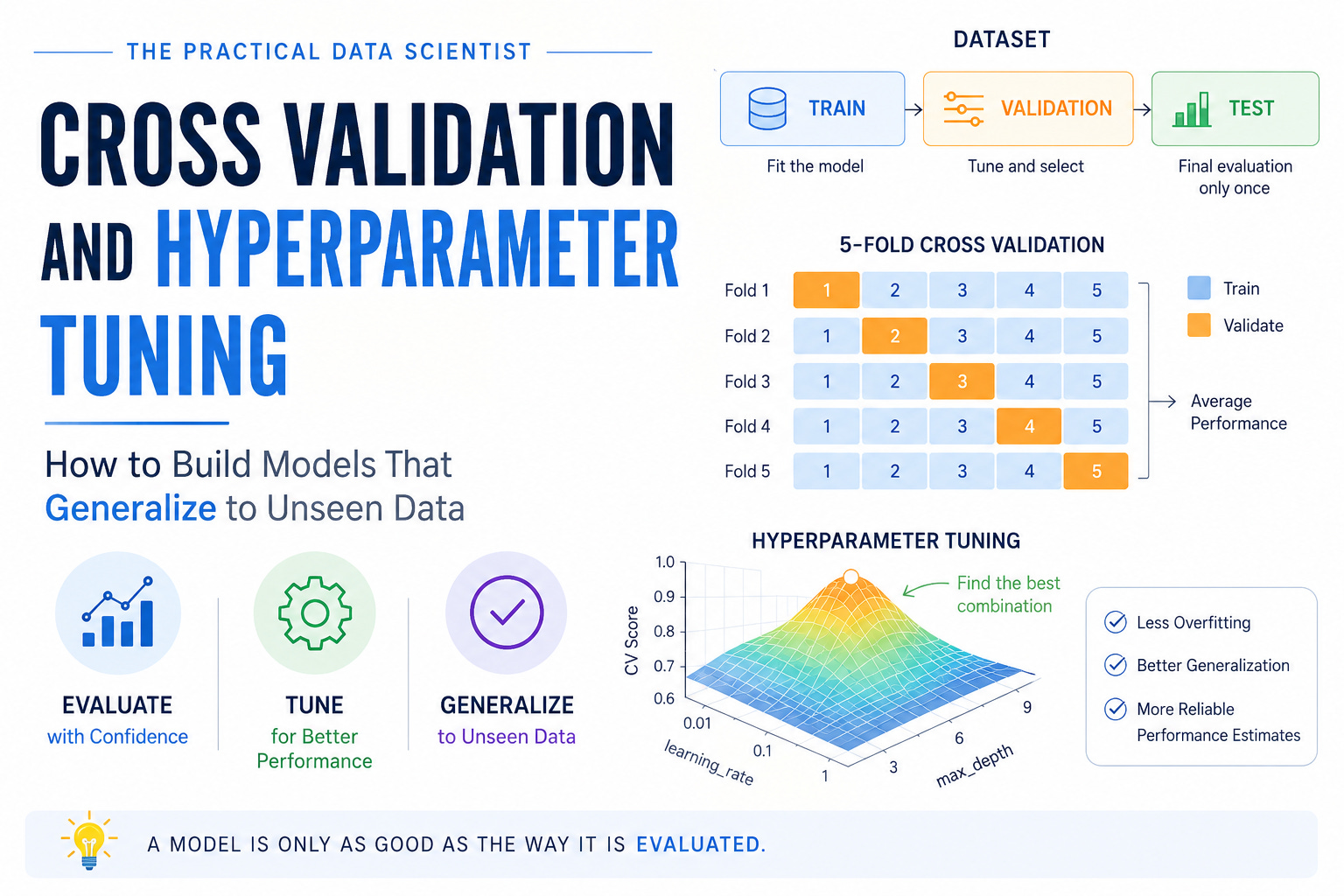
Train, Validation, and Test Sets
To understand cross validation and hyperparameter tuning, we first need to understand how data is typically divided during model development.
A machine learning model should not be evaluated on the same data it was trained on. Doing so can give an overly optimistic estimate of performance and make it difficult to detect overfitting.
For this reason, datasets are usually split into three parts:
Training Set
The training set is used to fit the model. During this phase, the algorithm learns patterns and relationships from the data.
Examples:
Estimating coefficients in Logistic Regression
Building trees in Random Forests
Learning residuals in XGBoost
The model has direct access to this data.
Validation Set
The validation set is used during model development. Its primary purposes are:
Hyperparameter tuning
Model selection
Comparing different algorithms
For example, we might use the validation set to answer questions like:
Should the Random Forest have 100 trees or 500 trees?
What learning rate should we use for XGBoost?
Is Logistic Regression performing better than Random Forest?
Importantly, the model does not learn directly from the validation set.
Instead, the validation set helps us make decisions about the model.
Test Set
The test set is used only once, after all model development is complete. Its purpose is to provide an unbiased estimate of how the final model will perform on unseen data.
Think of the test set as a final exam.
Just as students should not see the exam before taking it, the model should not use information from the test set while it is being developed.
The typical workflow looks like this:
Dataset
↓
Training Set
↓
Validation Set
↓
Test Set
Train on the training set
Tune on the validation set
Evaluate once on the test set
Many beginners focus heavily on training accuracy. However, what ultimately matters is how well the model performs on data it has never seen before.
🎤 Interview Q: Why can’t we tune hyperparameters using the test set?
A: Because the test set should remain untouched until the very end. Using it during model development can lead to overly optimistic performance estimates and poor generalization.
Cross Validation
In the previous section, we saw how datasets are typically divided into training, validation, and test sets. But there is a problem with this approach.
Suppose we randomly split our data and obtain a validation accuracy of 92%.
How much confidence should we have in that number? What if we had chosen a different validation set?
A different split could produce:
90% accuracy
94% accuracy
Or something entirely different
In other words, a single train-validation split may give us a misleading estimate of model performance. This is where cross validation comes in.
The Idea Behind Cross Validation
Instead of relying on a single validation set, cross validation repeatedly trains and evaluates the model on different subsets of the data.
By averaging performance across multiple splits, we obtain a more reliable estimate of how well the model will generalize to unseen data.
K-Fold Cross Validation
The most common approach is K-Fold Cross Validation.
The process works as follows:
Divide the dataset into K equal folds
Use K−1 folds for training
Use the remaining fold for validation
Repeat the process K times so that every fold serves as the validation set exactly once
Average the performance across all K runs
For example, in 5-fold cross validation:
Train on folds 1–4 and validate on fold 5
Train on folds 1–3 and 5, validate on fold 4
Continue until each fold has been used as the validation set
The final score is the average across all five runs.
Why Use Cross Validation?
Cross validation offers several advantages:
Makes better use of the available data
Reduces dependence on a single random split
Produces a more stable estimate of performance
Helps compare different models more fairly
For these reasons, cross validation is widely used in machine learning competitions and real-world projects.
The most commonly used values are:
5-Fold Cross Validation
10-Fold Cross Validation
In practice, 5-fold cross validation provides a good balance between computational cost and reliable performance estimates.
Cross validation does not improve the model itself. Instead, it improves our confidence in the model’s estimated performance.
🎤 Interview Q: Why do we use cross validation instead of a single train-test split?”
A: Cross validation reduces the dependence on a particular split and provides a more reliable estimate of how the model will perform on unseen data.”
Hyperparameter Tuning
So far, we’ve focused on evaluating models. But once we have a reliable evaluation strategy, another question naturally arises:
How do we choose the best version of a model?
This is where hyperparameter tuning comes in.
Hyperparameters are settings that control how a machine learning algorithm learns. Unlike model parameters, they are not learned from the data and must be specified before training begins.
For example: Random Forest
Number of trees (
n_estimators)Maximum depth (
max_depth)Minimum samples per split (
min_samples_split)
XGBoost
Learning rate
Maximum depth
Number of trees
Subsampling rate
Different hyperparameter values can lead to very different models and, consequently, very different performance.
Parameters vs Hyperparameters
It is important to distinguish between parameters and hyperparameters.
Parameters
Learned automatically from the data
Examples:
Coefficients in Logistic Regression
Split points in Decision Trees
Leaf values in XGBoost
Hyperparameters
Chosen before training
Control how the model learns
Examples:
Learning rate
Maximum depth
Number of trees
Grid Search
One approach to hyperparameter tuning is Grid Search. The idea is simple:
Define a set of possible values for each hyperparameter.
Train models using every possible combination.
Select the combination that produces the best validation performance.
For example:
max_depth: [3, 5, 7]
n_estimators: [100, 300, 500]Grid Search evaluates all nine combinations.
Advantages
Simple to understand
Exhaustive search
Limitations
Computationally expensive
Doesn’t scale well with many hyperparameters
Random Search
Instead of trying every combination, Random Search samples combinations randomly. For example, instead of evaluating all 100 possible combinations, we might randomly test 20.
Surprisingly, Random Search often performs just as well while requiring significantly less computation.
Advantages
More efficient
Scales better to large search spaces
Limitations
Not guaranteed to find the absolute best combination
The typical workflow looks like this:
Choose Hyperparameters
↓
Train Model
↓
Cross Validation
↓
Evaluate Performance
↓
Select Best Combination
Hyperparameter tuning is not about finding the perfect model. It is about finding a model that generalizes well to unseen data.
🎤 Interview Q: What is the difference between Grid Search and Random Search?
A: Grid Search evaluates every possible combination of hyperparameters, while Random Search samples combinations randomly. Random Search is often more computationally efficient and performs surprisingly well in practice.
Common Pitfalls
Cross validation and hyperparameter tuning are powerful tools, but they can also give misleading results if used incorrectly. Understanding these pitfalls is just as important as understanding the techniques themselves.
Data Leakage
Data leakage occurs when information from outside the training set unintentionally influences the model. Examples include:
Using future information to predict the past
Scaling the entire dataset before splitting
Performing feature selection on the full dataset
Data leakage can produce unrealistically high performance and often leads to poor results in production.
Tuning on the Test Set
The purpose of the test set is to estimate how the final model will perform on unseen data. If we repeatedly evaluate models on the test set and use those results to make decisions, the test set effectively becomes part of the training process.
This leads to overly optimistic performance estimates. The test set should only be used once, after all model development is complete.
Overfitting to the Validation Set
Trying too many models and hyperparameter combinations can cause us to unknowingly tailor our model to the validation data.
As a result, the validation score may no longer reflect true generalization performance. Cross validation helps reduce this problem, but it cannot eliminate it entirely.
Stratified K-Fold Cross Validation
For imbalanced datasets, a regular K-Fold split can produce folds with very different class distributions. This may lead to unstable evaluation metrics.
Stratified K-Fold preserves the class proportions in each fold, making performance estimates more reliable. For classification problems with class imbalance, Stratified K-Fold is often preferred over standard K-Fold.
Time Series Cross Validation
Traditional cross validation randomly shuffles observations. This approach breaks the temporal order of time series data and can introduce leakage from the future.
Instead, time series problems use expanding or rolling windows. The model is always trained on past observations and validated on future observations.
Important Insight
The biggest mistakes in machine learning often come not from the algorithms themselves, but from how models are evaluated. A sophisticated model evaluated incorrectly can be far worse than a simple model evaluated properly.
Common interview questions include:
What is data leakage?
Why shouldn’t we tune on the test set?
When would you use Stratified K-Fold?
Why is regular K-Fold inappropriate for time series data?
Being able to answer these questions demonstrates a strong understanding of practical machine learning, not just theory.
Rapid Fire Interview Questions and Final Takeaway
Why do we need a validation set?
The validation set is used for model selection and hyperparameter tuning, while the test set is reserved for the final evaluation.
Why can’t we tune hyperparameters using the test set?
Using the test set during model development can lead to overly optimistic performance estimates and poor generalization.
Why do we use cross validation?
Cross validation provides a more reliable estimate of model performance by reducing dependence on a single train-validation split.
What is the difference between parameters and hyperparameters?
Parameters are learned from the data during training, while hyperparameters are specified before training and control how the model learns.
Grid Search vs Random Search?
Grid Search evaluates every possible hyperparameter combination, while Random Search evaluates a random subset of combinations.
Random Search is often more computationally efficient.
When should you use Stratified K-Fold?
For classification problems with imbalanced classes, Stratified K-Fold ensures that each fold preserves the class distribution of the original dataset.
Why can’t we use regular K-Fold for time series data?
Randomly shuffling time series observations can introduce information from the future into the training set, leading to data leakage.
Time series data requires specialized validation strategies that preserve temporal order.
Final Takeaway
No matter how sophisticated a machine learning algorithm may be, its success ultimately depends on how it is evaluated.
Cross validation and hyperparameter tuning help us build models that generalize to unseen data rather than simply memorizing the training set.
If there’s one idea to remember, it’s this: A model is only as good as the way it is evaluated.
What’s Next?
In the next issue of The Practical Data Scientist, we’ll explore Regularization for Data Science Interviews.
We’ll dive into overfitting, the bias-variance tradeoff, and how techniques like Ridge (L2), Lasso (L1), and Elastic Net help machine learning models generalize better to unseen data.
Keep building, keep learning—wishing you the best in your data journey.
Amazing post 🔥🔥 with interview insights Please keep posting like this lots of knowledge.